I am a first-year Ph.D. at the CSAIL, MIT advised by Prof. Pulkit Agrawal. I am supported by the Ida Green Fellowship. I am grateful to have worked with some of the best researchers around the world, including Prof. C V Jawahar, Vinay Namboodiri, K. Madhav Krishna, Srinath Sridhar, Liam Paull, and Florian Shkurti.
Prior Experience. I was also a Data Scientist at Microsoft. I led a segment of the recommendation and suggestion team for the world’s biggest enterprise-facing email client - Outlook. The product features I worked on are used by more than 100 million users per month!
Creative Outlet. I am a musician. I sing and play guitar. I have toured and performed at several places with my previous band, Andrometa. I also LOVE traveling and used to create travel vlogs and music covers on YouTube! My brother is an amazing pianist and has taken over the channel now: Insen: Outdoor Pianist.
Research Interest
What drives my research is the idea of seeing robots become a commonplace - a part of our daily lives - imbibed with the ability to interact and manipulate the environment it lives in. In order to build such a generic enough robotic system that can perform most day-to-day tasks, scaling up the data needed to train them is, I believe, the primary challenge that we need to address in robotics.
My approach to addressing this is rethinking - (1) the kind of data we should be collecting (i.e. the learning objective), and (2) the method of collecting this data (i.e. scalable hardware). I am building towards the these two directions and hoping to make data collection for robotic manipulation as seemless as possible!
Selected Research
*Equal Authors / Highlighted Papers
Constrained 6-DoF Grasp Generation on Complex Shapes for Improved Dual-Arm Manipulation
Gaurav Singh, Sanket Kalwar, Md Faizal Karim,
Bipasha Sen (in advising capacity), Nagamanikandan Govindan, Srinath Sridhar and K Madhava Krishna,
IROS 2024project pageArXivConceptGraphs: Open-Vocabulary 3D Scene Graphs for Perception and Planning
Qiao Gu*, Ali Kuwajerwala*, Sacha Morin*, Krishna Murthy Jatavallabhula*,
Bipasha Sen, Aditya Agarwal, Kirsty Ellis, Celso Miguel de Melo, Corban Rivera, William Paul, Rama Chellappa, Chuang Gan, Joshua B. Tenenbaum, Antonio Torralba, Florian Shkurti, Liam Paull
ICRA 2024, CoRL-W 2024project pageArXivEDMP: Ensemble-of-costs-guided Diffusion for Motion Planning
Kallol Saha*, Vishal Mandadi*, Jayaram Reddy*, Ajit Srikanth, Aditya Agarwal,
Bipasha Sen (in advising capacity), Arun Singh, Madhava Krishna
ICRA 2024, CoRL-W 2023project pageArXivHyP-NeRF: Learning Improved NeRF Priors using a HyperNetwork
Bipasha Sen*, Gaurav Singh*, Aditya Agarwal*, Rohith Agaram, Madhava Krishna, Srinath Sridhar
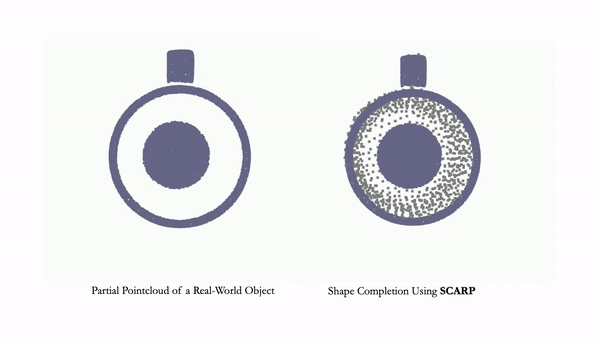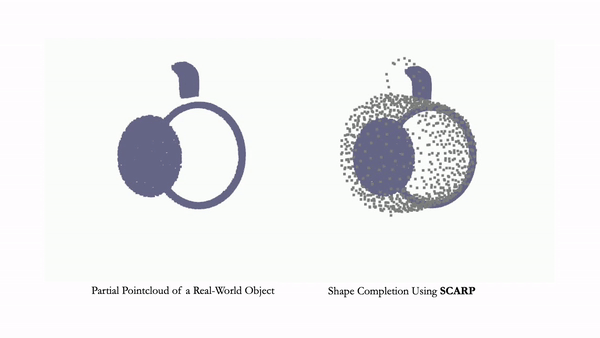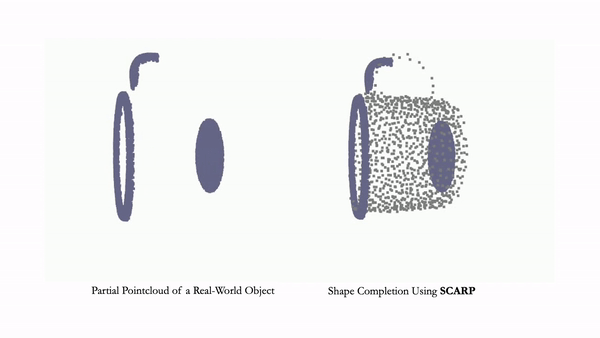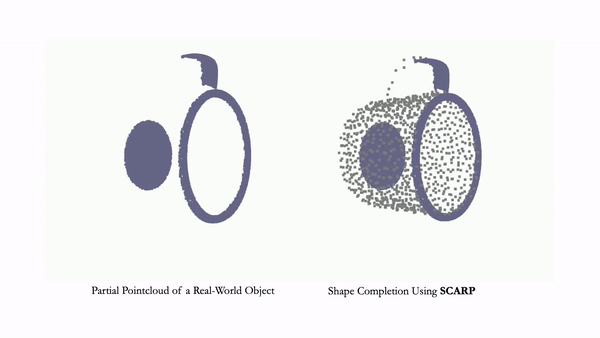
NeurIPS 2023project pageArXiv Learning generalizable NeRF priors over categories of scenes or objects has been challenging due to the high dimensionality of network weight space. To address the limitations of existing work on generalization, multi-view consistency and to improve quality, we propose HyP-NeRF, a latent conditioning method for learning generalizable category-level NeRF priors using hypernetworks. SCARP: 3D Shape Completion in ARbitrary Poses for Improved Grasping
Bipasha Sen*, Aditya Agarwal*, Gaurav Singh*, Brojeshwar Bhowmick, Srinath Sridhar, Madhava Krishna
ICRA 2023, RSS-W 2023project pagevideo We propose SCARP, a model that performs Shape Completion in ARbitrary Poses. Given a partial pointcloud of an object, SCARP learns a disentangled feature representation of pose and shape by relying on rotationally equivariant pose features and geometric shape features trained using a multi-tasking objective. INR-V: A Continuous Representation Space for Video-based Generative Tasks
We propose INR-V, a video representation network that learns a continuous space for video-based generative tasks. INR-V parameterizes videos using implicit neural representations (INRs), a multi-layered perceptron that predicts an RGB value for each input pixel location of the video. FaceOff: A Video-to-Video Face Swapping System
Aditya Agarwal*,
Bipasha Sen*, Rudrabha Mukhopadhyay, Vinay Namboodiri, C V Jawahar
WACV 2023project pagepapervideoTowards MOOCs for Lipreading: Using Synthetic Talking Heads to Train Humans in Lipreading at Scale
Aditya Agarwal*,
Bipasha Sen*, Rudrabha Mukhopadhyay, Vinay Namboodiri, C V Jawahar
WACV 2023paperApproaches and Challenges in Robotic Perception for Table-top Rearrangement and Planning
Aditya Agarwal*,
Bipasha Sen*, Shankara Narayanan V*, Vishal Reddy Mandadi*, Brojeshwar Bhowmick, K Madhava Krishna
Arxiv 2022papervideoPersonalized One-Shot Lipreading for an ALS Patient
Bipasha Sen*, Aditya Agarwal*, Rudrabha Mukhopadhyay, Vinay Namboodiri, C V Jawahar
BMVC 2021papervideoportal We propose a personalized network to lipread an ALS patient using only one-shot examples. Our approach significantly improves and achieves high top-5accuracy with 83.2% accuracy compared to 62.6% achieved by comparable methods for the patient. Apart from evaluating our approach on the ALS patient, we also extend it to people with hearing impairment relying extensively on lip movements to communicate.